- نقش NFT و Defi در جنگ اوکراین
- پیش بینی قیمت سکه Binance AUD: BNB در سال 2022 به چه قیمتی می تواند برسد؟
- تجارت BMEX در حال آمدن است. اماده ای؟
- یک مطالعه جامع از پیش بینی بازار از فرضیه بازار کارآمد تا رویکردهای پیش بینی بازار هوشمند اواخر
- نحوه سرمایه گذاری در ماسهبازی: از کجا می توان شن و ماسه را خریداری کرد
- بررسی سکه
- حاشیه اولیه در مقابل حاشیه تنوع
- 5 تعهد اجباری برای شروع تجارت تجارت مورد نیاز است
- چگونه می توان با مبلغ تجارت کرد؟
- رویاهای شکسته شده توسط لونا ، رمزنگاری که در سه روز سقوط کرد: "به نظر می رسید یک شرط امن است"

آخرین مطالب
امکانات وب


13. 48 مقایسه مدل برای نرخ استخدام با MSE.
در تمرین 13. 47 ، میانگین انحراف مطلق به عنوان معیار دقت پیش بینی معرفی شد. اندازه گیری دیگر میانگین خطای مربع (MSE) است که اندازه گیری اندازه متوسط خطاهای پیش بینی در واحدهای مربع است:
باقیمانده برای مدت زمان است و تعداد باقیمانده های موجود است.(توجه: برخی از نرم افزارها از این اندازه گیری به عنوان میانگین انحراف مربع یا MSD یاد می کنند.)
- محاسبه MSE برای باقیمانده از مدل های متوسط ، 2 ماهه ، 3 ماهه و 4 ماهه در حال حرکت تعیین شده در تمرین 13. 46 ، قسمت (C).
- مقدار متوسط متوسط حرکت با کوچکترین MSE مطابقت دارد؟
خطای متوسط مربع (MSE)
سوال 13. 49
13. 49 مقایسه مدل های مربوط به نرخ استخدام با MAPE.
MAD (تمرین 13. 47) میانگین بزرگی خطاهای پیش بینی را اندازه گیری می کند ، و MSE (تمرین 13. 48) اندازه متوسط مربع خطاهای پیش بینی را اندازه گیری می کند. برای قرار دادن خطاهای پیش بینی در چشم انداز ، اندازه گیری خطاها از نظر درصد می تواند مفید باشد. یکی از این اقدامات میانگین خطای درصد مطلق (MAPE) است:
در آن باقیمانده برای مدت زمان ، مشاهده واقعی برای دوره است و تعداد باقیمانده های موجود است.
میانگین خطای درصد مطلق (MAPE)
- محاسبه ماپه را به مکان صدمین برای باقیمانده از مدل های متوسط 1 ماهه ، 2 ماهه ، 3 ماهه و 4 ماهه که در تمرین 13. 46 ، قسمت (C) تعیین می شود ، محاسبه کنید.
- مقدار متوسط متوسط حرکت با کوچکترین مپ مطابقت دارد؟
(الف) MAPES عبارتند از: 1 ماه: 22. 0042 ، 2 ماه: 17. 3309 ، 3 ماه: 16. 5842 ، 4 ماه: 17. 2786.(ب) مپ 3 ماهه کوچکترین است.
نسبت های متوسط و فصلی حرکت می کند
شکل 13. 46 نشان داد که ما برای پیش بینی مشاهدات آینده یک سری روند ، نباید به میانگین حرکت متکی باشیم. با این حال ، ما می توانیم از میانگین های متحرک برای جداسازی حرکت روند کلی استفاده کنیم. با مقایسه مشاهدات فصلی نسبت به روند کلی ، ما وسیله ای برای تخمین مؤلفه فصلی داریم. به یاد بیاورید که با مثالهای 13. 16 و 13. 18 ، ما از متغیرهای شاخص فصلی در یک مدل رگرسیون برای تخمین اثر فصلی استفاده کردیم. در عمل ، رویکرد دیگری برای برآورد اثر فصلی بدون استفاده از رگرسیون وجود دارد.
این رویکرد از میانگین های متحرک استفاده می کند تا پایه ای برای سطح عمومی این سریال فراهم شود ، نه ارائه پیش بینی. به جای اینکه میانگین های متحرک را به آینده ارائه دهیم ، از آنها به عنوان خلاصه ای از گذشته استفاده می کنیم. به عنوان مثال ، اولین میانگین متحرک محاسبه شده در داده های سه ماهه را در نظر بگیرید:
اگر بخواهیم از این میانگین به عنوان پیش بینی استفاده کنیم ، در عوض ، این دوره 5 را پیش بینی می کند. در عوض ، ما به طور متوسط به عنوان نمایانگر سطح گذشته سری زمانی نگاه می کنیم. یک مشکل جزئی می تواند هنگام استفاده از میانگین متحرک برای برآورد سطح گذشته سری زمانی ایجاد شود. از آنجا که میانگین در حال حرکت بر اساس دوره های 1 ، 2 ، 3 و 4 بود ، از نظر فنی در دوره محور است. این مسئله مشکل ساز است زیرا ما می خواهیم مشاهداتی را که در کل دوره های زمانی تعداد با سطح سریال قرار می گیرد ، مقایسه کنیم تا مؤلفه فصلی را تخمین بزنیم. راه حل این مشکل را می توان با در نظر گرفتن میانگین حرکت بعدی در سری چهارم تشخیص داد:
میانگین متحرک قبلی نشان دهنده سطح سریال در است. اکنون ما یک میانگین در حال حرکت داریم و دیگری را نمایندگی می کنیم. با در نظر گرفتن میانگین این دو میانگین متحرک ، اکنون میانگین جدیدی داریم که در آن متمرکز خواهد شد. این میانگین به عنوان میانگین متحرک محور (CMA) گفته می شود.
میانگین متحرک محور (CMA)
مرحله دوم میانگین میانگین ها فقط در مواردی ضروری است که تعداد فصول ها حتی مانند داده های نیمساله ، سه ماهه یا ماهانه نیز باشد. با این حال ، اگر تعداد فصول عجیب باشد ، میانگین حرکت اولیه میانگین حرکت محور است. به عنوان نمونه ، اگر ما برای هفت روز هفته داده داده بودیم ، میانگین حرکتی از دهانه 7 را می گیریم. میانگین هفت دوره اول در آن متمرکز خواهد شد. اکنون می توانیم محاسبه میانگین های متحرک محور را با یک مثال نشان دهیم.
مثال 13. 28 استفاده از راه آهن سبک و میانگین های متحرک محور
اکسل یک روش مناسب برای محاسبه دستی میانگین های متحرک و میانگین های متحرک محور است. شکل 13. 47 تصویری از محاسبات اکسل را برای داده های استفاده از ریلی سبک نشان می دهد. میانگین متحرک اول 114279. 25 به عنوان میانگین چهار دوره اول محاسبه می شود. از نظر صفحه گسترده اکسل که در شکل 13. 47 نشان داده شده است ، وارد کنید
در سلول E3 و فرمول را به سلول E20 کپی کنید. در نتیجه ، می فهمیم که میانگین حرکت دوم 114721. 25 به عنوان میانگین دوره 2 تا 5 محاسبه می شود.
این مقدار را می توان در صفحه گسترده مشاهده کرد و با ورود به دست آمد
در سلول F4. این میانگین متحرک محور اول به درستی نشسته است. میانگین متحرک محور باقی مانده را می توان با کپی کردن فرمول در سلول F4 به سلول F20 یافت. آخرین میانگین متحرک موجود در سلول E20 شامل دوره های 18 تا 21 است و نشان دهنده آن است. میانگین متحرک بعدی به حداقل در سلول E19 نشان دهنده است. میانگین این دو میانگین آخرین میانگین حرکت نشان داده شده 130216. 86 (سلول F20) را نشان می دهد ، که نشان دهنده آن است.
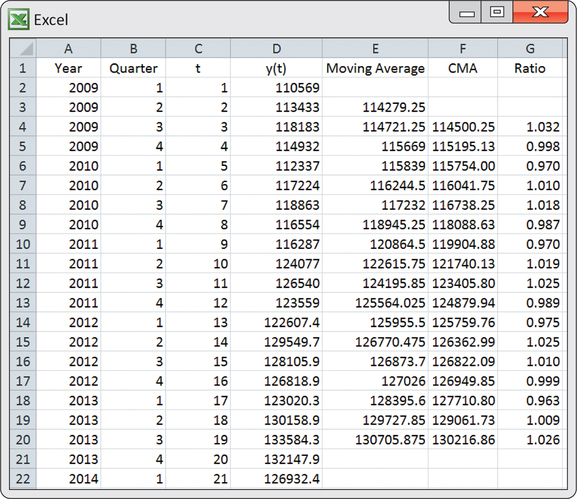
شکل 13. 47: شکل 13. 47 صفحه گسترده اکسل مورد استفاده در محاسبه میانگین های متحرک محور و نسبت های فصلی برای سری استفاده از ریلی سبک.
شکل 13. 48 میانگین های متحرک محور ترسیم شده در سری مسافر را نشان می دهد. مشابه شکل 13. 46 ، میانگین ها روند کلی را نشان می دهند. با این حال ، بر خلاف شکل 13. 46 ، این میانگین ها به موقع به عقب منتقل می شوند تا تخمین ای از این که سطح روند بر خلاف پیش بینی محل ممکن است باشد ، ارائه می دهد.
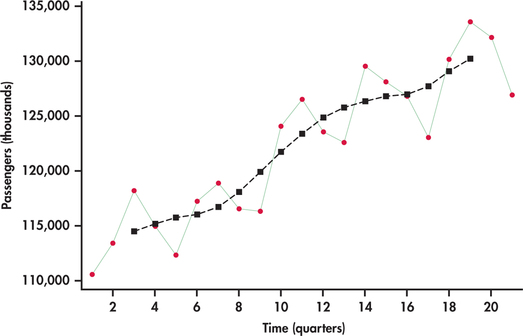
نسبت فصلی
اکنون که ما یک برآورد پایه مناسب برای سطح فرآیند از نظر تاریخی داریم ، می توانیم مؤلفه فصلی را محاسبه کنیم. احتمالاً متداول ترین روش محاسبه نسبت فصلی است. رویکرد نسبت بر اساس یک مدل فصلی چند برابر که قبلاً مورد مطالعه قرار گرفت ، یعنی ، یعنی ،
برای داده های مشاهده شده ، ایده اصلی در مورد نسبت های فصلی را می توان با تنظیم مجدد مدل Trend-Times-Seasonal مشاهده کرد:
این نسبت می گوید که ما می توانیم با تقسیم داده ها بر سطح سری ، همانطور که توسط مؤلفه روند تخمین زده می شود ، مؤلفه فصلی را جدا کنیم. بیایید ببینیم که چگونه این کار با ادامه مطالعه ما در مورد سریال Light Rail Rail Series انجام می شود.
مثال 13. 29 استفاده از راه آهن سبک و نسبت های فصلی
از مثال 13. 28 ، ما از میانگین های متحرک برای برآورد سطح سری زمانی استفاده کردیم که با گذشت زمان گرایش دارد. برای هر یک از سطوح تخمین زده شده توسط میانگین های متحرک محور ، ما نسبت فروش واقعی را که با میانگین متحرک محور تقسیم شده است محاسبه می کنیم. برای صفحه گسترده نشان داده شده در شکل 13. 47 ، وارد می شویم
در سلول G4 و سپس فرمول را در سلول G20 کپی کنید. نسبت های حاصل در آخرین ستون صفحه گسترده اکسل نشان داده شده است.
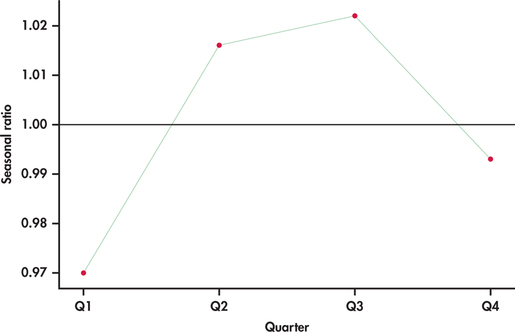
از آنجا که ما بیش از یک نسبت نسبت فصلی برای یک سه ماهه معین داریم ، این نسبت ها را به صورت چهارم متوسط می کنیم. یعنی ما میانگین را برای تمام نسبت های سه ماهه 1 محاسبه می کنیم ، سپس میانگین برای همه نسبت های سه ماهه 2 و غیره. این میانگین ها به برآورد نسبت فصلی ما تبدیل می شوند. جدول زیر نسبت های فصلی نتیجه را نشان می دهد.
| ربع | نسبت فصلی |
| 1 | 0. 970 |
| 2 | 1. 016 |
| 3 | 1. 022 |
| 4 | 0. 993 |
نسبت های فصلی تصویری از فراز و نشیب های معمولی در طول یک سال است. اگر از نظر درصد به نسبت ها فکر می کنید ، نسبت ها نشان می دهد که چگونه هر سه ماه با میانگین سطح برای هر چهار چهارم یک سال معین مقایسه می شود. به عنوان مثال ، نسبت سه ماهه اول 0. 97 یا 97 ٪ است که نشان می دهد تعداد مسافران برای فروش سه ماهه اول به طور معمول 3 ٪ پایین تر از میانگین برای هر چهار چهارم است. نسبت سه ماهه سوم 1. 022 یا 102. 2 ٪ است ، نشان می دهد که سوارکاری در سه ماهه سوم به طور معمول 2. 2 ٪ بالاتر از میانگین سالانه است. شکل 13. 49 عوامل فصلی را به صورت چهارم ترسیم می کند. خط مرجع مشخص شده در 1. 0 (100 ٪) یک کمک بصری برای تفسیر عوامل در مقایسه با میانگین متوسط رانندگی سه ماهه است. توجه کنید که چگونه نسبت های فصلی از الگویی که هر چهار چهارم در شکل 13. 46 تکرار می شود تقلید می کند (صفحه 693).
میانگین های متحرک محور یک پایه تاریخی از سطح روند را برای ما فراهم می کند. با این حال ، آنها برای پیش بینی این سریال در آینده در نظر گرفته نشده اند. با نسبت های فصلی در دست ، مرحله بعدی تنظیم فصلی این سریال است تا بتوانیم روند کلی را برای اهداف پیش بینی تخمین بزنیم.
مثال 13. 30 استفاده از ریلی سبک تنظیم شده فصلی
دوباره با تنظیم مجدد مدل روند-زمان-فصل ، ما به دست می آوریم
این نسبت به ما می گوید که چگونه یک سری را به صورت فصلی تنظیم کنیم. به طور خاص ، با تقسیم سریال اصلی بر اساس مؤلفه فصلی ، ما پس از آن با مؤلفه روند و بدون فصلی باقی مانده ایم. تقسیم هر مشاهده از سری اصلی با نسبت فصلی مربوطه که در مثال 13. 29 در سری نشان داده شده در شکل 13. 50 نشان داده شده است. این سری تنظیم شده ، فراز و نشیب های منظم داده های غیر قابل تنظیم اصلی را نشان نمی دهد. در این مرحله ، ما می توانیم با استفاده از رگرسیون همانطور که در شکل 13. 50 مشاهده می شود ، معادله خط روند را ارائه دهیم. مدل پیش بینی روند و فصل ما در این صورت است
جایی که SR نسبت فصلی برای سه ماهه مناسب مربوط به ارزش است.
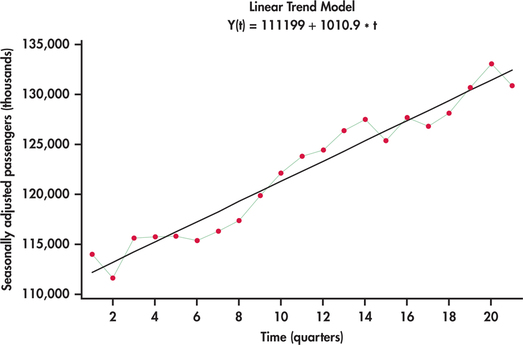
برای نشان دادن محاسبه یک پیش بینی ، توجه داشته باشیم که این سریال در سه ماهه اول به پایان رسید. این بدان معنی است که دوره بعدی در آینده سه ماهه دوم است. بر این اساس ، پیش بینی خواهد بود
بسیاری از سری های زمانی اقتصادی به طور معمول به صورت فصلی تنظیم می شوند تا در صورت وجود ، روند کلی را در تعداد آشکارتر کنند. سازمان های دولتی غالباً هر دو نسخه از یک سری زمانی را منتشر می کنند ، بنابراین مراقب باشید که هنگام استفاده از منابع دولتی ، داده های تنظیم شده فصلی را تجزیه و تحلیل می کنید.
برای سری مثال 13. 30 ، خروجی رگرسیون برای تناسب روند نشان می دهد که ضریب روند با ارزش کمتر از 0. 0005 قابل توجه است. در بعضی موارد ، ممکن است متوجه شویم که سری تنظیم شده فصلی روند قابل توجهی ندارد. در چنین مواردی ، ما نباید استفاده از مدل روند را غیر ضروری تحمیل کنیم. به عنوان مثال ، اگر سری تنظیم شده فصلی را برای نمایش رفتار تصادفی "مسطح" پیدا کنیم ، به سادگی می توانیم میانگین این سری را به آینده معرفی کنیم و بر ارزش متوسط تنظیم کنیم.
دانش خود را اعمال کنید
سوال 13. 50
13. 50 نسبت فصلی برای داده های فروش آمازون.
مورد 13. 1 در مثال 13. 18 (صفحات 675 - 676) ، مؤلفه فصلی با استفاده از متغیرهای شاخص برآورد شد. به عنوان یک گزینه دیگر ، فصلی را می توان با نسبت های فصلی که با استفاده از میانگین حرکت محاسبه می شود ، ضبط کرد.
- برای محاسبه نسبت های فصلی و گزارش مقادیر آنها از رویکرد متوسط حرکت کنید.
- سری تنظیم شده فصلی را تولید و ترسیم کنید. برداشت شما از این طرح چیست؟
- متناسب و گزارش یک مدل روند نمایی متناسب با سری تنظیم شده فصلی.
- پیش بینی برای فروش آمازون برای دوره آینده. چگونه این پیش بینی با پیش بینی های ارائه شده در مثال 13. 18 مقایسه می شود؟
مدل های هموار سازی نمایی
مدل های پیش بینی متوسط حرکت به شهود ما جذاب است. استفاده از میانگین چندین مورد از جدیدترین مقادیر داده برای پیش بینی مقدار بعدی سری زمانی به راحتی قابل درک است. با این حال ، دو انتقاد را می توان علیه مدل های متوسط حرکت کرد. اول ، پیش بینی ما برای دوره زمانی بعدی همه جز آخرین مشاهدات در مجموعه داده های ما را نادیده می گیرد. اگر 100 مشاهده دارید و از دهانه ای استفاده می کنید ، پیش بینی شما از 95 ٪ از داده های شما استفاده نمی کند! دوم ، مقادیر داده مورد استفاده در پیش بینی ما همه به طور یکسان وزن می شوند. در بسیاری از تنظیمات ، مقدار فعلی یک سری زمانی بیشتر به ارزش جدید و کمتر به مقادیر گذشته بستگی دارد. ما ممکن است پیش بینی های خود را بهبود بخشیم اگر در محاسبه پیش بینی خود جدیدترین مقادیر "وزن" بیشتری را ارائه دهیم. مدل های هموار سازی نمایی هر دو این انتقادات را نشان می دهند.
چندین تغییر در مدل صاف کننده نمایی اساسی وجود دارد. ما به جزئیات مدل صاف کننده نمایی ساده ، که ما از آن یاد می کنیم ، به سادگی ، مدل هموار سازی نمایی اشاره می کنیم. تغییرات پیچیده تری برای رسیدگی به سری های زمانی با ویژگی های خاص وجود دارد ، اما جزئیات این مدل ها فراتر از محدوده این فصل است. ما فقط به سناریوهایی اشاره می کنیم که این مدل های پیچیده تر مناسب هستند.
مدل هموار سازی نمایی
مدل هموار سازی نمایی از میانگین وزنی از مقدار مشاهده شده و مقدار پیش بینی شده به عنوان پیش بینی برای دوره زمانی t استفاده می کند. معادله پیش بینی است
وزن آن را ثابت صاف برای مدل هموار سازی نمایی نامیده می شود و به طور سنتی فرض می شود که دارای طیف وسیعی از آن است.
لازم به ذکر است که در ادبیات سری زمانی ، هیچ گونه سازگاری در فرض در مورد دامنه از نظر گنجاندن یا محرومیت از مقادیر 0 و 1 به عنوان گزینه های انتخابی وجود ندارد. حتی با نرم افزار تفاوت هایی وجود دارد. Excel اجازه می دهد تا 1 اما 0. JMP و MINITAB اجازه دهند 0 یا 1 باشد. در پایان این بخش ، توجه داشته باشیم که نرم افزار آماری حتی می تواند دامنه وسیع تری را برای آن فراهم کند.
انتخاب ثابت هموار سازی در مدل هموار سازی نمایی شبیه به انتخاب دهانه در مدل متوسط حرکت است-هم مستقیماً به صافی مدل مربوط می شود. مقادیر کوچکتر از هموار سازی بیشتر حرکات در سری زمانی مطابقت دارد. مقادیر بزرگتر بیشترین وزن را بر روی جدیدترین مقدار مشاهده شده قرار می دهد ، بنابراین پیش بینی ها به جدیدترین حرکت این سری نزدیک هستند. برخی از سریال ها برای بزرگتر مناسب تر هستند ، در حالی که برخی دیگر برای کوچکتر مناسب تر هستند. بیایید چند نمونه را برای به دست آوردن بینش کشف کنیم.
مثال 13. 31 سری فهرست PMI
در اولین روز کاری هر ماه ، موسسه مدیریت تأمین (ISM) گزارش تولید ISM در مورد تجارت را صادر می کند. این گزارش توسط بسیاری از اقتصاددانان ، رهبران مشاغل و سازمان های دولتی به عنوان یک فشار سنج مهم اقتصادی کوتاه مدت بخش تولید اقتصاد مشاهده می شود. در این گزارش ، یکی از شاخص های اقتصادی گزارش شده ، شاخص PMI است. مخفف PMI در ابتدا برای شاخص خرید مدیر ایستاده بود ، اما ISM اکنون فقط از مخفف استفاده می کند بدون هیچ گونه اشاره ای به معنای گذشته خود.
PMI یک شاخص کامپوزیت است که بر اساس نظرسنجی از مدیران خرید در تقریبا 300 شرکت تولیدی ایالات متحده است. مؤلفه های این شاخص مربوط به سفارشات جدید ، اشتغال ، عقب نشینی سفارش ، تحویل تأمین کننده ، موجودی ها و قیمت ها است. این شاخص به عنوان یک درصد اندازه گیری می شود - خواندن بالاتر از 50 ٪ نشان می دهد که اقتصاد تولید به طور کلی در حال گسترش است ، در حالی که یک خواندن زیر 50 ٪ نشان می دهد که به طور کلی در حال کاهش است.
شکل 13. 51 مقادیر PMI ماهانه را از ژانویه 2010 تا ژوئیه 2014 نشان می دهد. 28 همچنین پیش بینی های مربوط به هموار سازی نمایی با و.
سری PMI به دلیل مشاهدات پی در پی ، تمایل به نزدیکی یکدیگر را نشان می دهد. پیش از این ، ما از این رفتار به عنوان همبستگی مثبت یاد کردیم (صفحه 678). با نزدیک شدن مشاهدات پی در پی ، به نظر می رسد که یک ثابت هموار سازی بزرگتر برای ردیابی و پیش بینی این سریال بهتر کار می کند. در واقع ، از شکل 13. 51 می توانیم ببینیم که پیش بینی های مبتنی بر آهنگ بسیار نزدیک به سری PMI از پیش بینی های مبتنی بر. با ثابت صاف کردن 0. 1 ، مدل بخش اعظم حرکت (هم کوتاه مدت و هم بلند مدت) را در این سری صاف می کند. در نتیجه ، پیش بینی ها به آرامی نسبت به تغییر حرکت در سریال واکنش نشان می دهند.
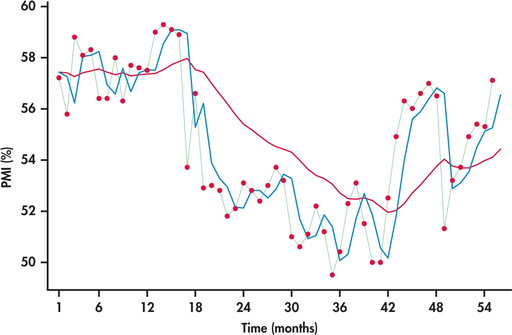
شکل 13. 51: شکل 13. 51 سری شاخص PMI ماهانه (ژانویه 2010 تا ژوئیه 2014) با دو مدل صاف کننده نمایی: با (قرمز) و با (آبی).
هنگامی که مشاهدات پی در پی ، پایداری نزدیک بودن به یکدیگر را نشان نمی دهد ، یک مقدار بزرگتر برای دیگر یک انتخاب ارجح نیست ، همانطور که با مثال بعدی می بینیم.
مثال 13. 32 بازده دیزنی
در مثال 13. 1 (صفحات 645 - 646) ، ما ابتدا بازده هفتگی سهام دیزنی را با یک طرح زمانی مطالعه کردیم. طرح زمان به همراه آزمون Runs (مثال 13. 5 ، صفحه 653) و ACF (مثال 13. 6 ، صفحات 653 - 654) نشان داد که سری بازده با یک سری تصادفی سازگار است.
شکل 13. 52 (الف) 20 مشاهده آخر این سری را با پیش بینی های مبتنی بر. با ثابت صاف کردن 0. 7 ، پیش بینی های یک مرحله ای به ارزش جدیدترین مشاهده در سری Retus نزدیک است. از آنجا که بازده ها به طور تصادفی در حال تندرست هستند ، می فهمیم که پیش بینی ها نیز به طور تصادفی در حال تندرست هستند اما اغلب به طور قابل توجهی از مشاهدات واقعی که در تلاش برای پیش بینی هستند ، خارج می شوند. با نگاهی دقیق به شکل 13. 52 (الف) ، می بینیم که وقتی بازده بالاتر از میانگین است ، پیش بینی برای بازده دوره بعدی نیز بالاتر از حد متوسط است. اما ، با تصادفی بودن ، بازده دوره بعدی به راحتی می تواند پایین تر از حد متوسط باشد و در نتیجه پیش بینی به طور قابل توجهی از مارک خارج می شود. بر اساس یک استدلال مشابه ، بازدهی که زیر متوسط است می تواند منجر به پیش بینی دوره بعدی شود. به عبارت دیگر ، بزرگتر وزن غیر ضروری را به حرکات تصادفی می بخشد ، که با توجه به ماهیت آنها ، هیچ ارزش پیش بینی کننده ای ندارند.
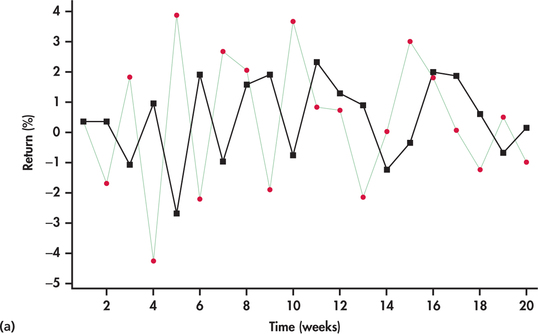
شکل 13. 52 (ب) پیش بینی های مبتنی بر ثابت صاف کننده کوچکتر را نشان می دهد ،. با یک ثابت صاف کننده کوچکتر ، ما می بینیم که یک منحنی پیش بینی صاف تر با پیش بینی ها نسبت به حرکات تصادفی کوتاه مدت و کوتاه مدت بازده واکنش نشان نمی دهد. از آنجا که ما به تدریج صاف کردن ثابت را کوچکتر می کنیم ، منحنی پیش بینی به میانگین کلی مشاهدات همگرا می شود.
برای دیدن اینکه چگونه مدل هموار سازی نمایی از داده ها متفاوت از مدل متوسط حرکت استفاده می کند ، یک جبر کوچک مورد نیاز است. ما با معادله پیش بینی برای مدل هموار سازی نمایی شروع می کنیم و تصور می کنیم مقدار سری زمانی را برای دوره زمانی پیش بینی کنیم ، که تعداد مقادیر مشاهده شده در سری زمانی کجاست:
این نسخه جایگزین معادله پیش بینی دقیقاً نشان می دهد که پیش بینی ما به مقادیر سری زمانی بستگی دارد. توجه کنید که محاسبه می تواند تمام راه بازگشت به پیش بینی اولیه را ردیابی کند. این معمول است که با استفاده از مقدار واقعی دوره زمانی اول به عنوان پیش بینی برای دوره زمانی اول ، مدل هموار سازی نمایی را آغاز کنید. اکسل و JMP در واقع مدل هموار سازی نمایی را به این روش آغاز می کنند. با این حال ، پیش فرض مینیتاب استفاده از میانگین شش مشاهده اول به عنوان پیش بینی اولیه است. این پیش فرض را می توان به گونه ای تغییر داد که پیش بینی اولیه اولین مشاهده است. ما همچنین از پشتوانه می آموزیم که پیش بینی برای استفاده از تمام مقادیر موجود در سری زمانی ، نه فقط جدیدترین مقادیر مانند یک مدل متوسط در حال حرکت. وزنهای موجود در مشاهدات به صورت نمایی از نظر عاملی کاهش می یابد که معادله را از چپ به راست به پایین می خوانید. این عامل به عنوان عامل میرایی شناخته می شود.
عامل کمرنگ کننده
در حالی که نسخه دوم معادله پیش بینی ما برخی از خصوصیات مهم مدل هموار سازی نمایی را نشان می دهد ، استفاده از نسخه اول معادله برای محاسبه پیش بینی ها ساده تر است.
مثال 13. 33 پیش بینی PMI
پیش بینی اوت 2014 PMI را با استفاده از یک مدل هموار سازی نمایی با. سریال PMI به پایان رسید. این بدان معنی است که پیش بینی اوت 2014 دوره پیش بینی 56 است:
ما به مقدار پیش بینی شده نیاز داریم تا محاسبه خود را تمام کنیم. با این حال ، برای محاسبه ، ما به مقدار پیش بینی شده نیاز خواهیم داشت! در حقیقت ، این الگوی ادامه دارد و ما باید قبل از محاسبه ، تمام پیش بینی های گذشته را محاسبه کنیم. ما چند پیش بینی اول را در اینجا محاسبه می کنیم و محاسبات باقی مانده را برای نرم افزار باقی می گذاریم. با توجه به این ، محاسبات به شرح زیر آغاز می شود:
نرم افزار محاسبات ما را برای رسیدن به پیش بینی 55. 248 ادامه می دهد. ما از این مقدار برای تکمیل محاسبه پیش بینی خود برای:
با ارزش پیش بینی شده برای آگوست 2014 از مثال 13. 33 ، پیش بینی ماه سپتامبر فقط به یک محاسبه نیاز دارد:
پس از مشاهده PMI واقعی برای آگوست 2014 () ، می توانیم این مقدار را در معادله پیش بینی قبلی وارد کنیم. به روزرسانی پیش بینی های مدل های هموار سازی نمایی فقط مستلزم پیگیری پیش بینی دوره آخر و ارزش مشاهده شده دوره آخر است. در مقابل ، مدل های متوسط حرکت می کند که آخرین مقادیر مشاهده شده سری زمانی را پیگیری کنیم.
در مثالهای 13. 31 و 13. 32 ، ما موقعیت هایی را نشان دادیم که در آن ثابت های هموار سازی بزرگتر یا کوچکتر ارجح هستند. با این حال ، بحث های ما فقط در مورد مقادیر 0. 1 و 0. 7 برای. این گزینه ها کاملاً دلخواه هستند و فقط برای اهداف مصور استفاده می شدند. در عمل ، ما می خواهیم با امید به دست آوردن پیش بینی های محکم تر ، ثابت صاف را تنظیم کنیم.
یک رویکرد این است که مقادیر مختلف همراه با اندازه گیری دقت پیش بینی را امتحان کنید و ارزش آن را پیدا کنید. به عنوان مثال ، ما می توانیم مقدار آن را جستجو کنیم که میانگین خطای مربع (MSE) را به حداقل می رساند. MSE اندازه گیری دقت پیش بینی است که در تمرین 13. 48 (صفحه 694) معرفی شده است. از صفحات گسترده می توان برای انجام محاسبات بر روی مقادیر مختلف ممکن استفاده کرد تا به ما کمک کند تا در یک انتخاب معقول از آن استفاده کنیم. به عنوان یک گزینه جایگزین ، بسته های نرم افزاری آماری (مانند JMP و MINITAB) گزینه ای را برای تخمین ثابت صاف کننده "بهینه" فراهم می کند. پیش از این ما ذکر کردیم که یک کلاس عمومی تر از سریال های زمانی معروف به مدل های ARIMA (صفحه 682) وجود دارد. به نظر می رسد که معادله پیش بینی هموار سازی نمایی معادله بهینه برای یک مدل بسیار ویژه Arima است. 29 این مدل ویژه Arima دارای یک پارامتر خاص است که مستقیماً با ثابت هموار سازی مرتبط است. بنابراین ، با برآورد پارامتر ، ما تخمین می زنیم.
مثال 13. 34 ثابت هموار سازی بهینه برای سری فهرست PMI
شکل 13. 53 برای برآورد ثابت صاف کننده بهینه ، خروجی از JMP و MINITAB را نشان می دهد. JMP مقدار را 0. 7953 گزارش می دهد و Minitab این مقدار را 0. 7908 گزارش می کند. تفاوت جزئی در این مقادیر به این دلیل است که برنامه های نرم افزاری برای برآورد پارامترهای ARIMA از روشهای مختلفی استفاده می کنند.
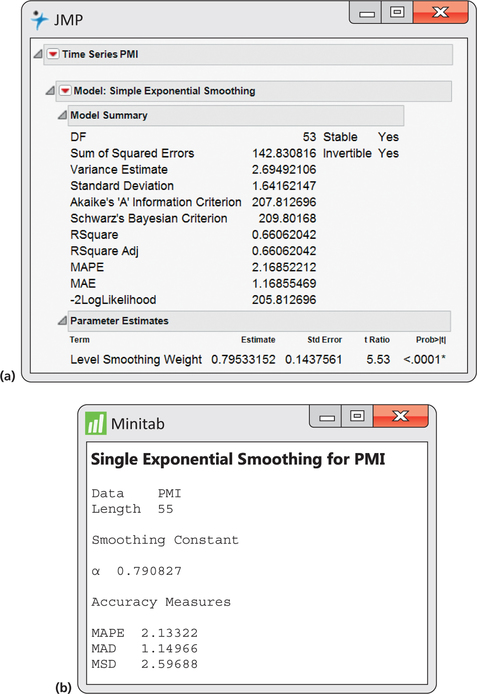
شکل 13. 53: شکل 13. 53 (الف) JMP ثابت صاف کننده بهینه گزارش شده است.(ب) مینیتاب ثابت صاف کننده بهینه را گزارش کرد.
هنگامی که ما مدل هموار سازی نمایی (صفحه 700) را تعریف کردیم ، اظهار داشتیم که ثابت صاف کننده به طور سنتی فرض می شود که در محدوده قرار می گیرد. یک مقدار ثابت صاف کننده در این محدوده جذابیت بصری به عنوان میانگین وزنی مشاهده و پیش بینی است که در آن وزنه ها درصد مثبت هستند و تا 100 ٪ اضافه می کنند. به عنوان مثال ، A از 0. 40 به معنای وزن 40 ٪ در مقدار مشاهده و وزن 60 ٪ در مقدار پیش بینی است.
با این حال ، معلوم می شود که وقتی مدل هموار سازی نمایی از منظر وصل شدن به یک مدل ARIMA مشاهده می شود ، ممکن است ثابت صاف کننده مقدار بیشتری از 1 را بدست آورد. در محدوده. JMP در تخمین خود از ثابت صاف ، گزینه های مختلفی را در اختیار کاربر قرار می دهد: (1) محدود به دامنه ؛(2) محدود به دامنه ؛(3) اجازه می دهد هر مقدار ممکن و بدون محدودیت باشد. بدون ورود به دلایل فنی ، می توان نشان داد که تا زمانی که در محدوده باشد ، مدل پیش بینی پایدار تلقی می شود. اگر تخمین نرم افزار بیشتر از 1 باشد ، چند گزینه وجود دارد. گزینه اول این است که پیش بروید و از آن در مدل هموار سازی نمایی استفاده کنید. از نظر فنی در انجام این کار اشتباه نیست. با این حال ، پزشکانی وجود دارند که از ثابت صاف کننده بیشتر از 1 ناراحت هستند و ترجیح می دهند محدودیت سنتی داشته باشند. در چنین حالتی ، بهترین گزینه بعدی از نظر به حداقل رساندن MSE ، انتخاب مقدار 1 برای است.
مشابه مدل متوسط در حال حرکت ، مدل صاف کننده نمایی ساده برای سری زمانی پیش بینی و بدون روند قوی مناسب است. همچنین برای ردیابی حرکات فصلی طراحی نشده است. تغییرات در مدل صاف کننده نمایی ساده برای رسیدگی به سری های زمانی با یک روند (هموار سازی نمایی مضاعف و هموار سازی نمایی هولت) ، با فصلی (هموار سازی نمایی فصلی) و با هر دو روند و فصلی (هموار سازی نمایی زمستان) ایجاد شده است. نرم افزار شما ممکن است یک یا چند مورد از این مدل های هموار سازی را ارائه دهد.
کتاب دستیار معامله گر...
ما را در سایت کتاب دستیار معامله گر دنبال می کنید
برچسب : نویسنده : عزتالله انتظامی بازدید : 51
لینک دوستان
- کرم سفید کننده وا
- دانلود آهنگ جدید
- خرید گوشی
- فرش کاشان
- بازار اجتماعی رایج
- خرید لایسنس نود 32
- هاست ایمیل
- خرید بانه
- خرید بک لینک
- کلاه کاسکت
- موزیک باران
- دانلود آهنگ جدید
- ازن ژنراتور
- نمایندگی شیائومی مشهد
- مشاوره حقوقی تلفنی با وکیل
- کرم سفید کننده واژن
- اگهی استخدام کارپ
- دانلود فیلم
- آرشیو مطالب
- فرش مسجد
- دعا
- لیزر موهای زائد
- رنگ مو
- شارژ
خبرنامه
